Priority processing is in preview and available by invitation only. Register here to be notified when it becomes more broadly available.This preview is provided without a service-level agreement and isn’t recommended for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews. Prerequisites
- An Azure subscription - Create one for free.
- A Microsoft Foundry project with a model of the deployment type
GlobalStandard or DataZoneStandard deployed.
- Acceptance into the priority processing preview. Register here to be notified when priority processing becomes more broadly available.
- API version
2025-10-01-preview or later.
Overview
Benefits
- Predictable low latency: Faster, more consistent token generation.
- Easy-to-use flexibility: Like standard pay-as-you-go processing, access priority processing on a flexible, pay-as-you-go basis instead of requiring provisioning and reservations in advance.
Key use cases
- Consistent, low latency for responsive user experiences.
- Pay-as-you-go simplicity with no long-term commitments.
- Business-hour or bursty traffic that benefits from scalable, cost-efficient performance. Optionally, you can combine priority processing with Provisioned Throughput Units (PTU) for steady-state capacity and cost optimization.
Limits
-
Ramp limit: Rapid increases to your priority processing tokens per minute might lead to hitting ramp rate limits. If you exceed the ramp rate limit, the service might send extra traffic to standard processing instead.
-
Quota: Priority processing uses the same quota as standard processing. This means your deployment with priority processing enabled consumes quota from your existing standard allocation.
Priority processing support
Global standard
Data Zone standard
Global standard model availability
| Region | gpt-4.1, 2025-04-14 |
|---|
| eastus 2 | ✅ |
| swedencentral | ✅ |
| westus3 | ✅ |
Data zone standard model availability
| Region | gpt-4.1, 2025-04-14 |
|---|
| eastus 2 | ✅ |
| swedencentral | ✅ |
| westus3 | ✅ |
Model and region availability might expand during the preview period. Check this page for updates.
Known issues
Priority processing currently has these limitations, and fixes are underway:
-
Long context limit for gpt-4.1: The service doesn’t support requests that exceed 128,000 tokens and returns an HTTP 400 error.
-
No support for PTU spillover: The service doesn’t yet support PTU spillover to a priority-processing–enabled deployment. If you need spillover behavior, implement your own logic, such as by using Azure API Management.
-
Incorrect service_tier value when using streaming in the Responses API: When streaming responses through the Responses API, the
service_tier field might incorrectly return “priority”, even if capacity constraints or ramp limits caused the request to be served by the standard tier. In this case, the expected value for service_tier is “default”.
Enable priority processing at the deployment level
You can enable priority processing at the deployment level and (optionally) at the request level.
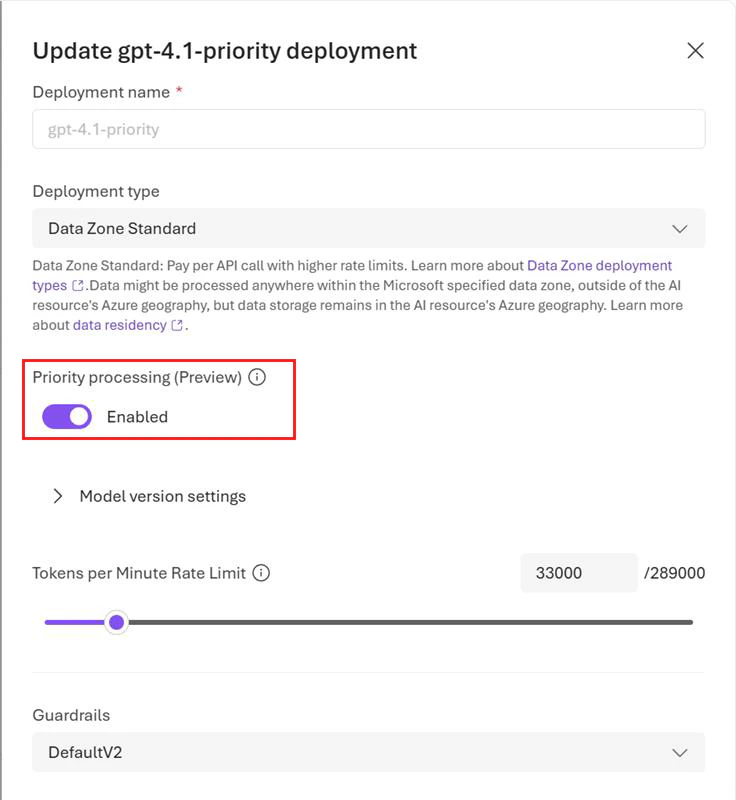
In the Microsoft Foundry portal, you can enable priority processing during deployment setup. Turn on the Priority processing (preview) toggle on the deployment details page when creating the deployment or update the setting of a deployed model by editing the deployment details.
If you prefer to use code to enable priority processing at the deployment level, you can do so via the REST API for deployment by setting the service_tier attribute as follows: "properties" : {"service_tier" : "priority"}. Allowed values for the service_tier attribute are default and priority. default implies standard processing, while priority enables priority processing.
View usage metrics
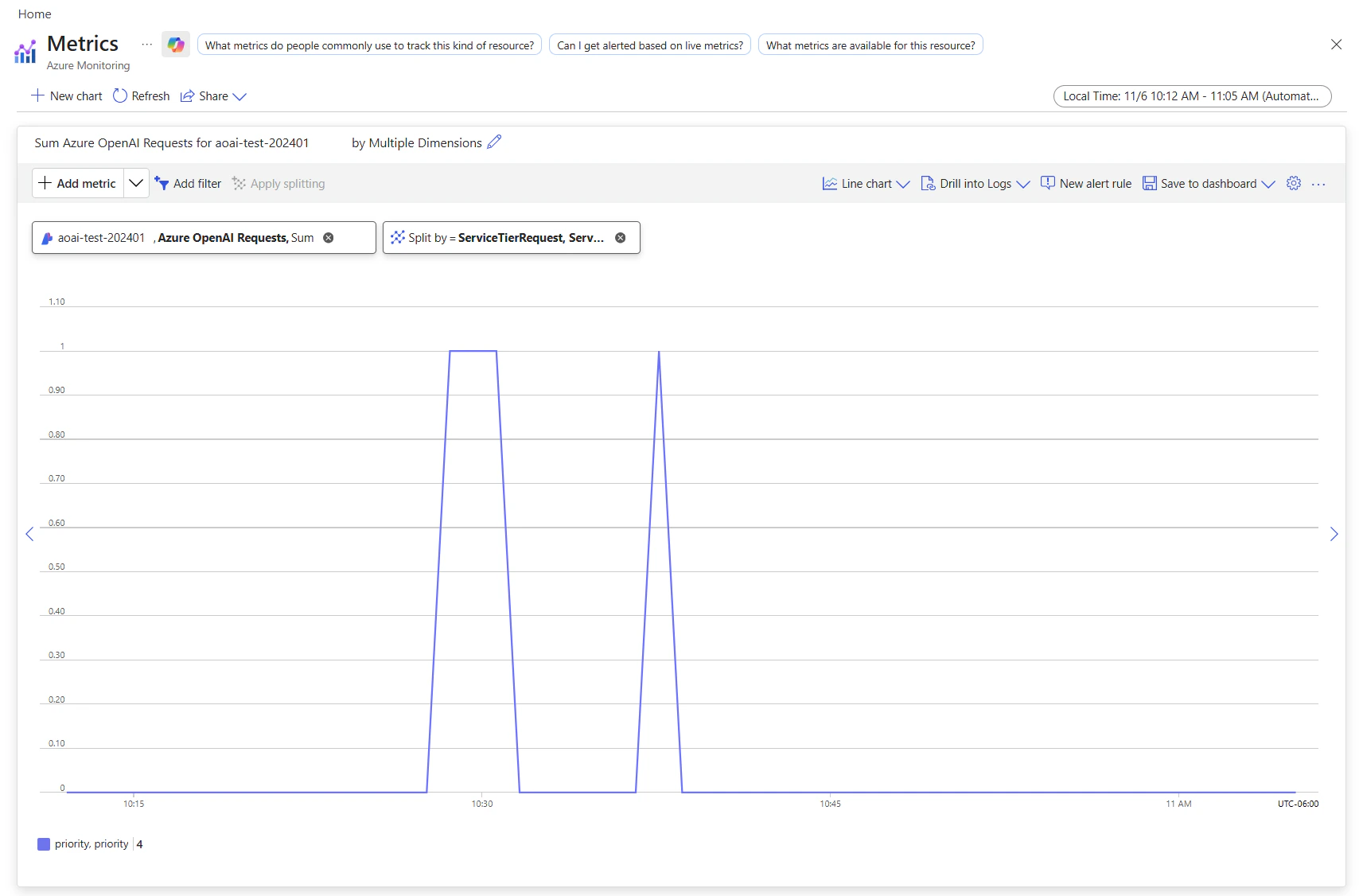
You can view the utilization measure for your resource in the Azure Monitor section in the Azure portal.
To view the volume of requests processed by standard processing versus priority processing, split by the service tier (standard or priority) that was in the original request:
- Sign in to https://portal.azure.com.
- Go to your Azure OpenAI resource and select the Metrics option from the left navigation.
- On the metrics page, add the Azure OpenAI requests metric. You can also select other metrics like Azure OpenAI latency, Azure OpenAI usage, and others.
- Select Add filter to select the standard deployment for which priority processing requests were processed.
- Select Apply splitting to split the values by ServiceTierRequest and ServiceTierResponse.
For more information about monitoring your deployments, see Monitor Azure OpenAI.
Monitor costs
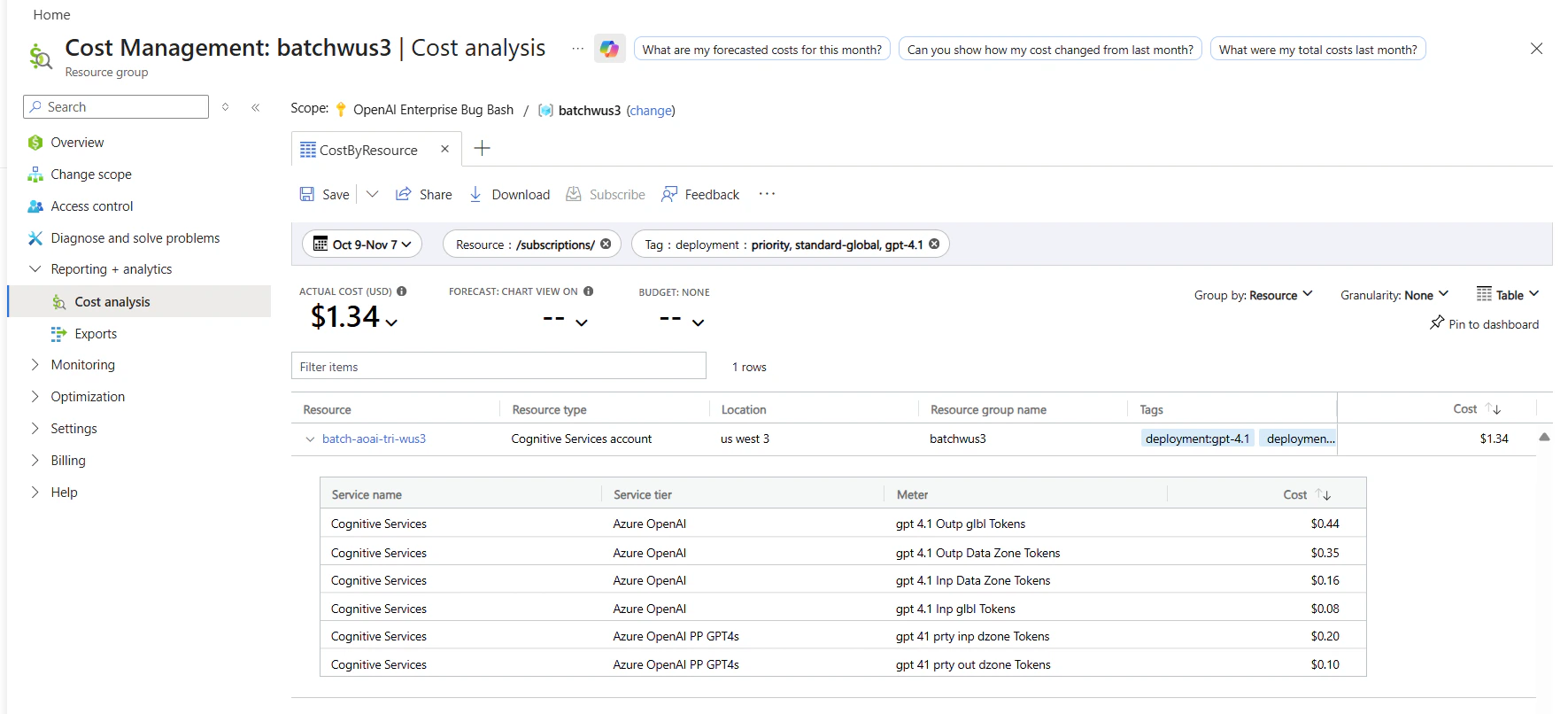
You can see a breakdown of costs for priority and standard requests in the Azure portal’s cost analysis page by filtering on deployment name and billing tags as follows:
- Go to the cost analysis page in the Azure portal.
- (Optional) Filter by resource.
- To filter by deployment name: Add a filter for billing Tag > select deployment as the value, then choose your deployment name.
For information about pricing for priority processing, see the Azure OpenAI Service pricing overview.
Enable priority processing at the request level
Enabling priority processing at the request level is optional. Both the chat completions API and responses API have an optional attribute service_tier that specifies the processing type to use when serving a request. The following example shows how to set service_tier to priority in a responses request.
curl -X POST https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AZURE_OPENAI_AUTH_TOKEN" \
-d '{
"model": "gpt-4.1",
"input": "This is a test",
"service_tier": "priority"
}'
service_tier attribute to override the deployment-level setting. service_tier can take the values auto, default, and priority.
-
If you don’t set the attribute, it defaults to
auto.
-
service_tier = auto means the request uses the service tier configured in the deployment.
-
service_tier = default means the request uses the standard pricing and performance for the selected model.
-
service_tier = priority means the request uses the priority processing service tier.
The following table summarizes which service tier processes your requests based on the deployment-level and request-level settings for service_tier.
| Deployment-level setting | Request-level setting | Request processed by service tier |
|---|
| default | auto, default | Standard |
| default | priority | Priority processing |
| priority | auto, priority | Priority processing |
| priority | default | Standard |
Latency target
| Topic | gpt-4.1, 2025-04-14 |
|---|
| Latency Target Value | 99% > 80 Tokens Per Second* |
Ramp rate limits
To ensure consistently high performance for all customers, while still providing flexible, on-demand pricing, priority processing enforces ramp rate limits. Currently, the ramp rate limit is defined as increasing traffic by more than 50% tokens per minute in less than 15 minutes.
Downgrade conditions
If priority processing performance degrades and a customer’s traffic ramps up too quickly, the service might downgrade some priority requests to standard processing. The service bills requests processed by the standard service tier at standard rates. These requests aren’t eligible for the priority processing latency target. Requests processed by the standard service tier include service_tier = default in the response.
If you routinely encounter ramp rate limits, consider purchasing PTU instead of or in addition to priority processing.
Troubleshooting
| Issue | Cause | Resolution |
|---|
| HTTP 400 error on long prompts | gpt-4.1 doesn’t support requests exceeding 128,000 tokens in priority processing. | Keep total request tokens under 128,000. Split long prompts into smaller requests. |
| Requests downgraded to standard tier | Traffic ramped up more than 50% tokens per minute in under 15 minutes, hitting the ramp rate limit. | Increase traffic gradually. Consider purchasing PTU for steady-state capacity. |
| PTU spillover not working | Priority processing doesn’t yet support PTU spillover to a priority-processing–enabled deployment. | Implement custom spillover logic, such as by using Azure API Management. |
service_tier returns incorrect value during streaming | When streaming via the Responses API, service_tier might report "priority" even when the request was served by the standard tier. | Check billing records to confirm which tier actually processed the request. |
API support
| API Version |
|---|
| Latest supported preview API release: | 2025-10-01-preview |
Related content