Safety evaluation for fine-tuning (preview)
The advanced capabilities of fine-tuned models come with increased responsible AI challenges related to harmful content, manipulation, human-like behavior, privacy issues, and more. Learn more about risks, capabilities, and limitations in the Overview of Responsible AI practices and Transparency Note. To help mitigate the risks associated with advanced fine-tuned models, we have implemented additional evaluation steps to help detect and prevent harmful content in the training and outputs of fine-tuned models. These steps are grounded in the Microsoft Responsible AI Standard and Azure Microsoft Foundry Models content filtering.- Evaluations are conducted in dedicated, customer specific, private workspaces;
- Evaluation endpoints are in the same geography as the Foundry resource;
- Training data isn’t stored in connection with performing evaluations; only the final model assessment (deployable or not deployable) is persisted; and
Data evaluation
Before training starts, the service evaluates your data for potentially harmful content across the harm categories listed earlier. If harmful content is detected above the specified severity level, your training job fails, and you receive a message informing you of the categories of failure. Sample message:Model evaluation
After training completes but before the fine-tuned model is available for deployment, the service evaluates the resulting model for potentially harmful responses using Azure’s built-in risk and safety metrics. Using the same approach to testing used for the base large language models, the evaluation simulates a conversation with your fine-tuned model to assess the potential to output harmful content across the harm categories listed earlier. If a model is found to generate output containing content detected as harmful at above an acceptable rate, you’ll be informed that your model isn’t available for deployment, with information about the specific categories of harm detected: Sample message: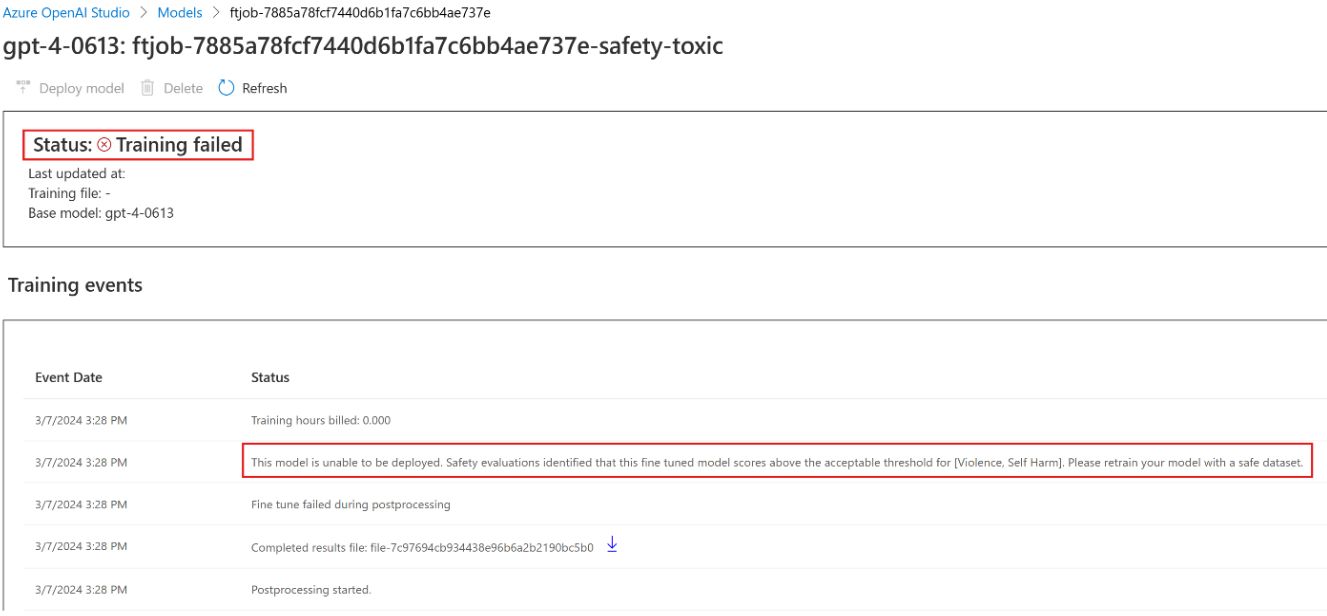
Next steps
- To request modified content safety thresholds for fine-tuning, submit the request form.
- Explore the fine-tuning capabilities in the Foundry fine-tuning tutorial.
- Review fine-tuning model regional availability.
- Learn more about Foundry quotas.