- Set up the SDK client for evaluation.
- Choose evaluators for quality, safety, and agent behavior.
- Create a test dataset and run an evaluation.
- Interpret results and integrate them into your workflow.
Prerequisites
- A Foundry project with an agent.
- An Azure OpenAI deployment with a GPT model that supports chat completion (for example,
gpt-4oorgpt-4o-mini). - Azure AI User role on the Foundry project.
Some evaluation features have regional restrictions. See supported regions for details.
Set up the client
Install the Foundry SDK and set up authentication:Choose evaluators
Evaluators are functions that assess your agent’s responses. Some evaluators use AI models as judges, while others use rules or algorithms. For agent evaluation, consider this set:| Evaluator | What it measures |
|---|---|
| Task Adherence | Does the agent follow its system instructions? |
| Coherence | Is the response logical and well-structured? |
| Violence | Does the response contain violent content? |
- Agent evaluators — Evaluate how effectively agents handle tasks, tools, and user intent.
- Quality evaluators — Measure the overall quality of generated responses.
- Text similarity evaluators — Compare generated text against reference answers using NLP metrics.
- Safety evaluators — Identify potential content and security risks in generated output.
Create a test dataset
Create a JSONL file with test queries for your agent. Each line contains a JSON object with aquery field:
Run an evaluation
When you run an evaluation, the service sends each test query to your agent, captures the response, and applies your selected evaluators to score the results. First, configure your evaluators. Each evaluator needs a data mapping that tells it where to find inputs:{{item.X}}references fields from your test data, likequery.{{sample.output_items}}references the full agent response, including tool calls.{{sample.output_text}}references just the response message text.
initialization_parameters. Some evaluators might require additional fields, like ground_truth or tool definitions. For more information, see the evaluator documentation.
Interpret results
Evaluations typically complete in a few minutes, depending on the number of queries. Poll for completion and retrieve the report URL to view the results in the Microsoft Foundry portal under the Evaluations tab: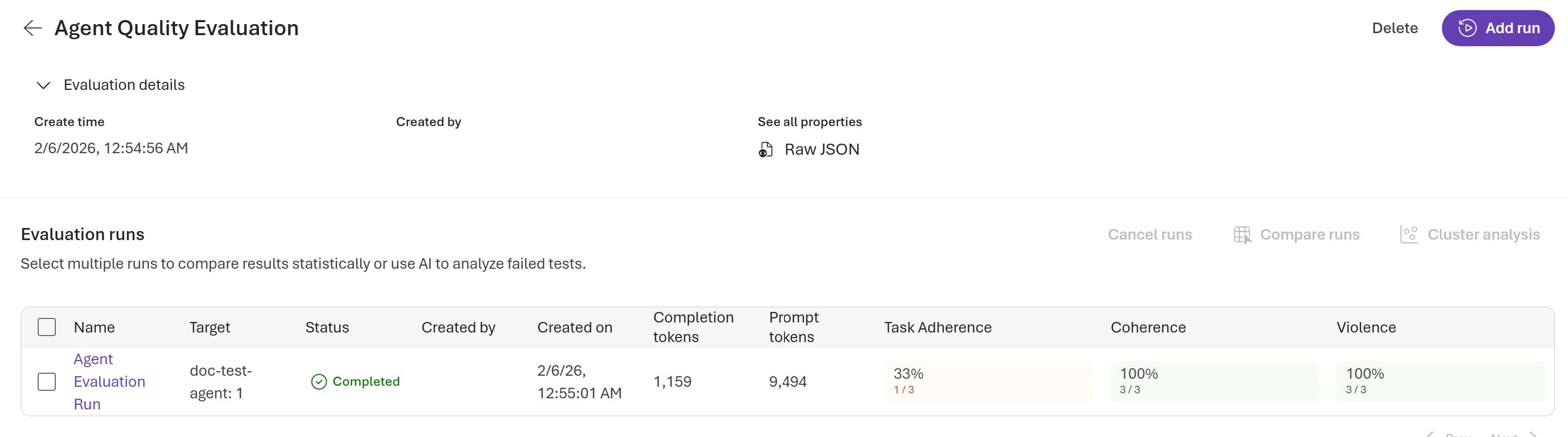
Aggregated results
At the run level, you can see aggregated data, including pass and fail counts, token usage per model, and results per evaluator:Row level output
Each evaluation run returns output items per row in your test dataset, providing detailed visibility into your agent’s performance. Output items include the original query, agent response, individual evaluator results with scores and reasoning, and token usage:Integrate into your workflow
- CI/CD pipeline: Use evaluation as a quality gate in your deployment pipeline. For detailed integration, see Run evaluations with GitHub Actions.
- Production monitoring: Monitor your agent in production by using continuous evaluation. For setup instructions, see Set up continuous evaluation.
Optimize and compare versions
Use evaluation to iterate and improve your agent:- Run evaluation to identify weak areas. Use cluster analysis to find patterns and errors.
- Adjust agent instructions or tools based on findings.
- Reevaluate and compare runs to measure improvement.
- Repeat until quality thresholds are met.