Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don’t recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews. Features
- Agent Evaluation: Automate pre-production assessment of Microsoft Foundry agents in your CI/CD workflow.
- Evaluators: Use any evaluators from the Foundry evaluator catalog.
- Statistical Analysis: Evaluation results include confidence intervals and test for statistical significance to determine if changes are meaningful and not due to random variation.
Evaluator categories
Prerequisites
How to set up AI agent evaluations
Parameters
| Name | Required? | Description |
|---|
| azure-ai-project-endpoint | Yes | Endpoint of your Microsoft Foundry Project. To find this value, open your project in Foundry portal and copy the endpoint from the Overview page. |
| deployment-name | Yes | The name of an Azure AI model deployment to use for evaluation. Find existing deployments under Models + endpoints in the Foundry portal. |
| data-path | Yes | Path to the data file that contains the evaluators and input queries for evaluations. |
| agent-ids | Yes | ID of one or more agents to evaluate in format agent-name:version (for example, my-agent:1 or my-agent:1,my-agent:2). Multiple agents are comma-separated and compared with statistical test results. |
| baseline-agent-id | No | ID of the baseline agent to compare against when evaluating multiple agents. If not provided, the first agent is used. |
To find your agent ID and version, open your project in Foundry portal, go to Agents, select your agent, and copy the Agent ID from the details pane. The version is the deployment version number (for example, my-agent:1). Data file
The input data file should be a JSON file with the following structure:
| Field | Type | Required? | Description |
|---|
| name | string | Yes | Name of the evaluation dataset. |
| evaluators | string[] | Yes | List of evaluator names to use. Check out the list of available evaluators in your project’s evaluator catalog in Foundry portal: Build > Evaluations > Evaluator catalog. |
| data | object[] | Yes | Array of input objects with query and optional evaluator fields like ground_truth, context. Automapped to evaluators; use data_mapping to override. |
| openai_graders | object | No | Configuration for OpenAI-based evaluators (label_model, score_model, string_check, etc.). |
| evaluator_parameters | object | No | Evaluator-specific initialization parameters (for example, thresholds, custom settings). |
| data_mapping | object | No | Custom data field mappings (autogenerated from data if not provided). |
Basic sample data file
{
"name": "test-data",
"evaluators": [
"builtin.fluency",
"builtin.task_adherence",
"builtin.violence"
],
"data": [
{
"query": "Tell me about Tokyo disneyland"
},
{
"query": "How do I install Python?"
}
]
}
Additional sample data files
| Filename | Description |
|---|
| dataset-tiny.json | Dataset with small number of test queries and evaluators. |
| dataset.json | Dataset with all supported evaluator types and enough queries for confidence interval calculation and statistical test. |
| dataset-builtin-evaluators.json | Built-in Foundry evaluators example (for example, coherence, fluency, relevance, groundedness, metrics). |
| dataset-openai-graders.json | OpenAI-based graders example (label models, score models, text similarity, string checks). |
| dataset-custom-evaluators.json | Custom evaluators example with evaluator parameters. |
| dataset-data-mapping.json | Data mapping example showing how to override automatic field mappings with custom data column names. |
AI agent evaluations workflow
To use the GitHub Action, add the GitHub Action to your CI/CD workflows. Specify the trigger criteria, such as on commit, and the file paths to trigger your automated workflows.
To minimize costs, don’t run evaluation on every commit.
name: "AI Agent Evaluation"
on:
workflow_dispatch:
push:
branches:
- main
permissions:
id-token: write
contents: read
jobs:
run-action:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Azure login using Federated Credentials
uses: azure/login@v2
with:
client-id: ${{ vars.AZURE_CLIENT_ID }}
tenant-id: ${{ vars.AZURE_TENANT_ID }}
subscription-id: ${{ vars.AZURE_SUBSCRIPTION_ID }}
- name: Run Evaluation
uses: microsoft/ai-agent-evals@v3-beta
with:
# Replace placeholders with values for your Foundry Project
azure-ai-project-endpoint: "<your-ai-project-endpoint>"
deployment-name: "<your-deployment-name>"
agent-ids: "<your-ai-agent-ids>"
data-path: ${{ github.workspace }}/path/to/your/data-file
AI agent evaluations output
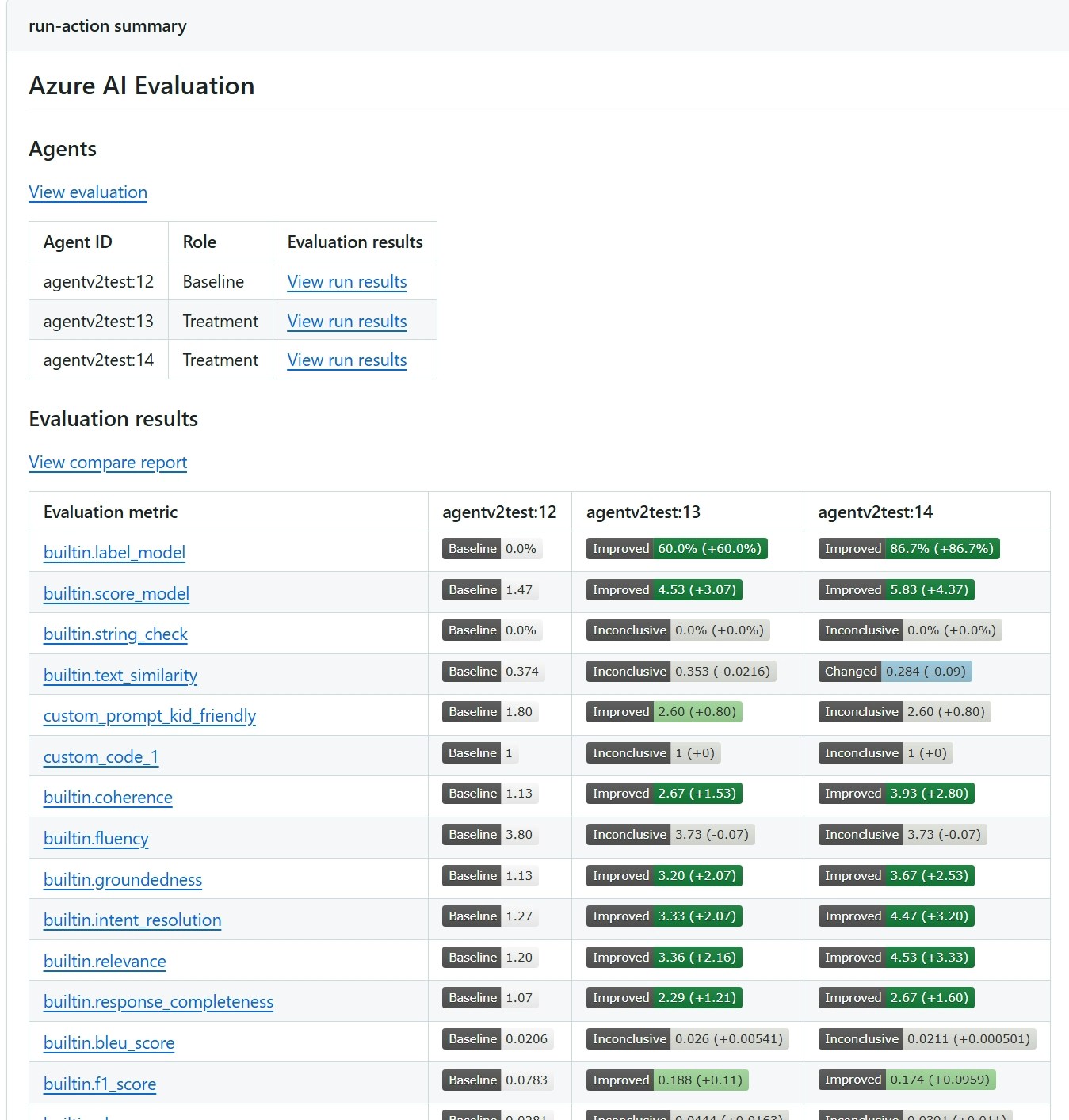
Evaluation results are output to the summary section for each AI Evaluation GitHub Action run under Actions in GitHub. The report shows evaluation scores for each metric, confidence intervals, and — when you evaluate multiple agents — a pairwise statistical comparison that indicates whether differences are meaningful or within random variation.
The following screenshot shows a sample report comparing two agents.
Related content