- Download a sample dataset and prepare it for analysis.
- Create environment variables for your resources endpoint and API key.
- Use one of the following models: text-embedding-ada-002 (Version 2), text-embedding-3-large, text-embedding-3-small models.
- Use cosine similarity to rank search results.
Prerequisites
- An Azure subscription - Create one for free
- A Microsoft Foundry or Azure OpenAI resource with the text-embedding-ada-002 (Version 2) model deployed. This model is currently only available in certain regions.
- Python 3.10 or later version
- The following Python libraries:
openai,num2words,matplotlib,plotly,scipy,scikit-learn,pandas,tiktoken. - Jupyter Notebooks
Set up
Python libraries
If you haven’t already, you need to install the following libraries:Download the BillSum dataset
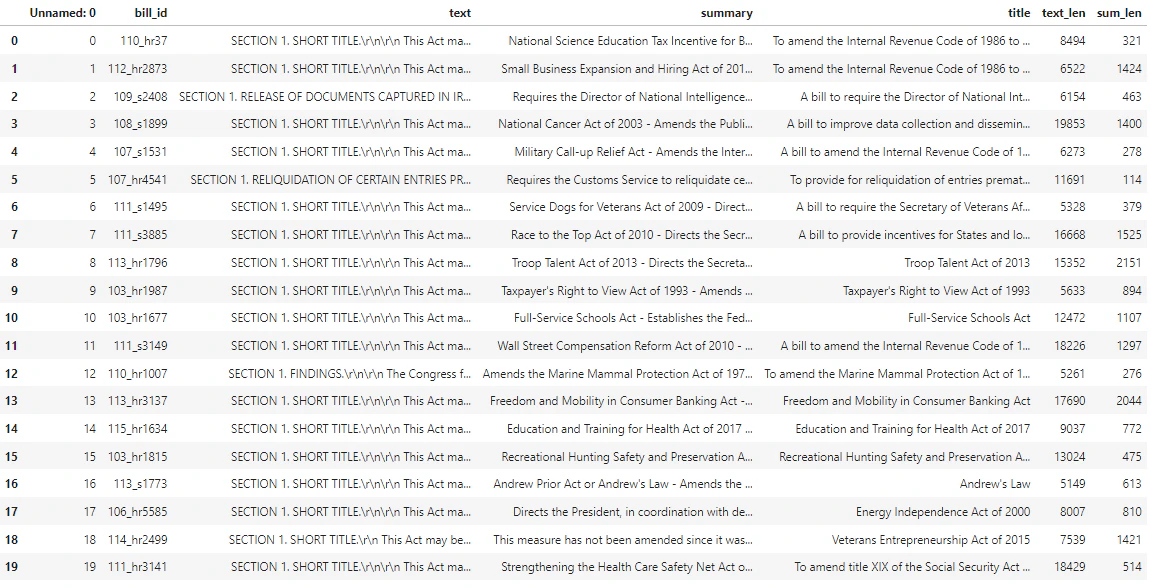
BillSum is a dataset of United States Congressional and California state bills. For illustration purposes, we’ll look only at the US bills. The corpus consists of bills from the 103rd-115th (1993-2018) sessions of Congress. The data was split into 18,949 train bills and 3,269 test bills. The BillSum corpus focuses on mid-length legislation from 5,000 to 20,000 characters in length. More information on the project and the original academic paper where this dataset is derived from can be found on the BillSum project’s GitHub repository This tutorial uses thebill_sum_data.csv file that can be downloaded from our GitHub sample data.
You can also download the sample data by running the following command on your local machine:
Microsoft Entra ID based authentication is currently not supported for embeddings with the v1 API.
Retrieve key and endpoint
To successfully make a call against Azure OpenAI, you need an endpoint and a key.| Variable name | Value |
|---|---|
ENDPOINT | The service endpoint can be found in the Keys & Endpoint section when examining your resource from the Azure portal. Alternatively, you can find the endpoint via the Deployments page in Microsoft Foundry portal. An example endpoint is: https://docs-test-001.openai.azure.com/. |
API-KEY | This value can be found in the Keys & Endpoint section when examining your resource from the Azure portal. You can use either KEY1 or KEY2. |
KEY1 or KEY2. Always having two keys allows you to securely rotate and regenerate keys without causing a service disruption.
Environment variables
Create and assign persistent environment variables for your API key.print(dataframe_name) rather than just calling the dataframe_name directly as is often done at the end of a code block.
Run the following code in your preferred Python IDE:
Import libraries
df.
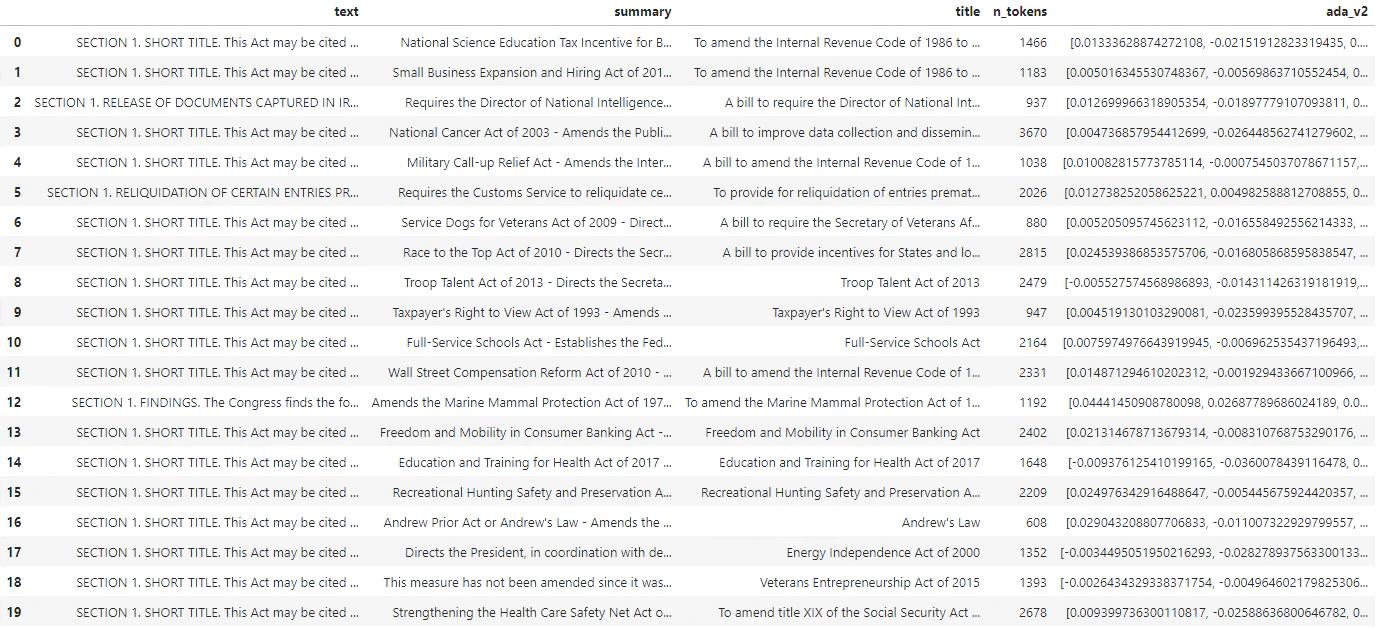
df_bills which will contain only the columns for text, summary, and title.
In this case all bills are under the embedding model input token limit, but you can use the technique above to remove entries that would otherwise cause embedding to fail. When faced with content that exceeds the embedding limit, you can also chunk the content into smaller pieces and then embed the chunks one at a time.
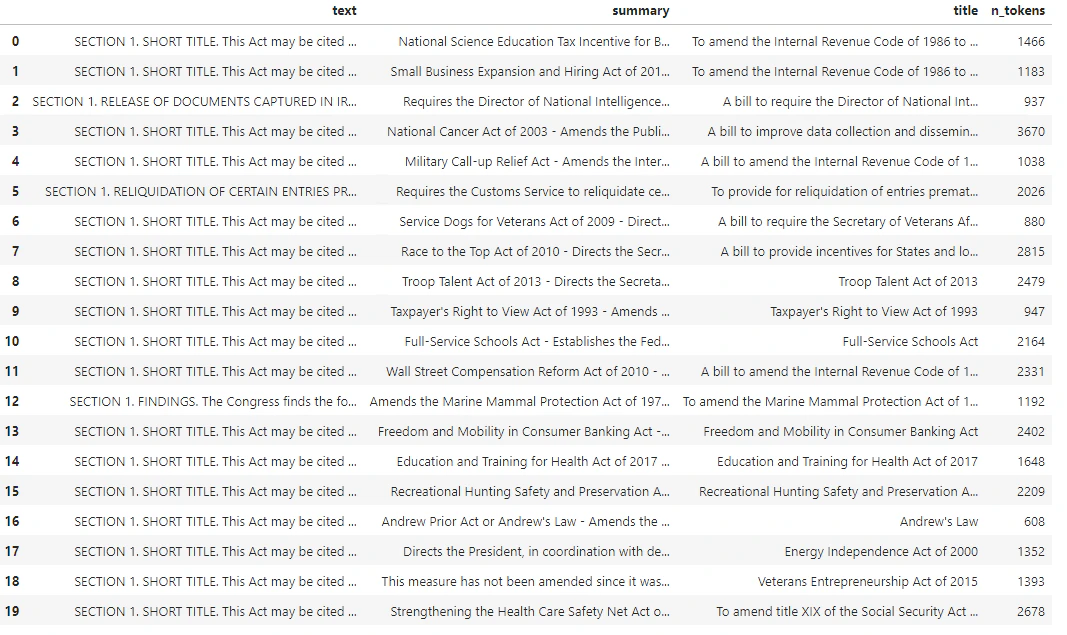
decode variable, you’ll find it matches the first number in the n_tokens column.
n_tokens column is simply a way of making sure none of the data we pass to the model for tokenization and embedding exceeds the input token limit of 8,192. When we pass the documents to the embeddings model, it will break the documents into tokens similar (though not necessarily identical) to the examples above and then convert the tokens to a series of floating point numbers that will be accessible via vector search. These embeddings can be stored locally or in an Azure Database to support Vector Search. As a result, each bill will have its own corresponding embedding vector in the new ada_v2 column on the right side of the DataFrame.
In the example below we’re calling the embedding model once per every item that we want to embed. When working with large embedding projects you can alternatively pass the model an array of inputs to embed rather than one input at a time. When you pass the model an array of inputs the max number of input items per call to the embedding endpoint is 2048.

Troubleshooting
- 401/403: Verify
AZURE_OPENAI_API_KEYis set and matches your resource key. - 404: Verify
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENTmatches your deployment name. - Invalid URL: Verify
AZURE_OPENAI_ENDPOINTis your resource endpoint, for examplehttps://<resource-name>.openai.azure.com.