Audio and speech
How to use batch synthesis for text to speech avatar - Speech service
Learn how to create text to speech avatar batch synthesis.
The batch synthesis API for text to speech avatar lets you synthesize text asynchronously into a talking avatar as a video file. Publishers and video content platforms can use this API to create avatar video content in a batch. That approach can be suitable for different use cases like training materials, presentations, or advertisements.
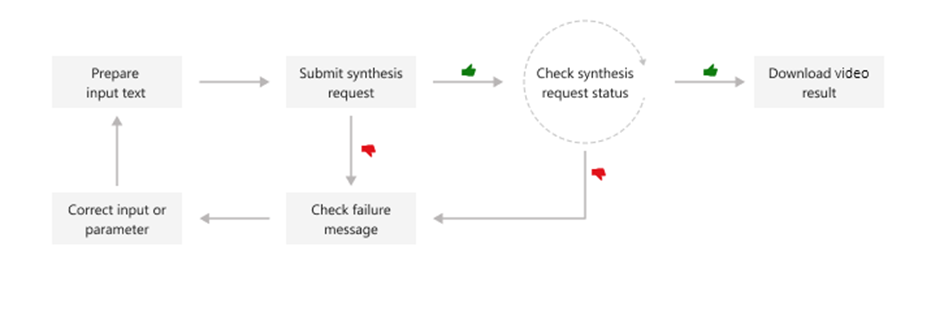
The synthetic avatar video will be generated asynchronously after the system receives text input. The generated video output can be downloaded in batch mode synthesis. You submit text for synthesis, poll for the synthesis status, and download the video output when the status shows success. The text input formats must be plain text or Speech Synthesis Markup Language (SSML) text.
This diagram provides a high-level overview of the workflow.